Bag-of-Words (BoW) 이란?
Bag-of-Words (BoW)는 문장을 단어들의 "가방"으로 간주하고, 각 단어의 등장 빈도수를 세어 벡터로 만드는 방식이다. 여기서 단어의 순서나 문맥은 무시되는 것이 중요한 특징이다.
아래 3개 문장이 있다고 가정하자.
1. He is a good boy
2. She is a good girl good
3. Boy and girl are good
1. 먼저 문장을 단어로 분리하며 소문자로 변환하고, 불용어(stop word)를 제거한다.
여기서 불용어에는 (he, she, is, a, and, are) 가 있다. 그러면 아래와 같이 변환된다.
1. good boy
2. good girl good
3. boy girl good
2. 단어 사용 빈도를 내림차순으로 저장하고 벡터로 변환한다.
| Vocabulary | Frequency |
| good | 4 |
| boy | 2 |
| girl | 2 |
그럼 [good, boy, girl] 벡터에 따라 입력할 수 있고 아래와 같이 변환된다.
1. [1 1 0]
2. [2 0 1]
3. [1 1 1]
Binary BOW일 경우에는 1과 0만 존재하므로 아래와 같다.
1. [1 1 0]
2. [1 0 1]
3. [1 1 1]
장점
1. 간단하고 직관적이다.
2. 고정적인 입력값이 존재하기 때문에 ML 알고리즘 훈련에 유리하다. (one-hot encoding의 단점 해결)
단점
1. 어휘의 희소성 (Sparsity): 어휘 사전의 크기가 커질수록 각 문서 벡터는 대부분 0으로 채워지는 희소 벡터(sparse vector)가 된다. 이는 계산 효율성과 메모리 문제를 야기할 수 있다. (one-hot encoding과 동일)
2. 단어의 순서를 무시한다 : 예를들어 boy good 과 good boy는 다른 문장이지만 BOW 알고리즘에서는 판단할 수 없다.
3. 테스트 데이터에 없는 단어는 벡터로 표현할 방법이 없다. (one-hot encoding과 동일)
4. 단어의 중요도를 판단할 수 없기 때문에 의미를 파악할 수 없다. (one-hot encoding과 동일)
N-Gram 이란?
BoW 방식이 단어의 순서를 고려하지 않기 때문에 문맥 정보를 파악할 수 없다.
따라서 N-Gram을 사용하여 해당 알고리즘의 단점을 보완하게 된다.
N-Gram은 연속된 N개의 단어 묶음을 의미한다. 즉 기존의 단어 단위 대신 N개의 단어 묶음을 하나의 단어로 사용하겠다는 것이다.
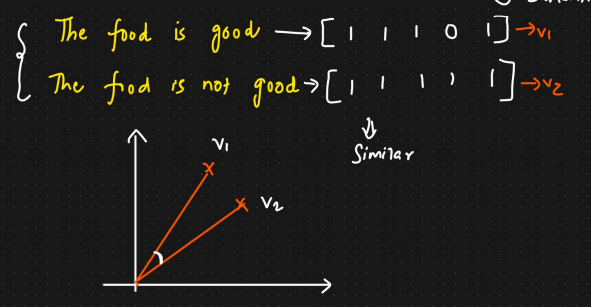
아래와 같이 두 가지 문장이 있을 때 불용어를 제외하면 food, no, good 세 가지 단어가 추출된다.
S1. the food is good
S2. the food is not good
| food | not | good | food good | food not | not good | |
| S1 | 1 | 0 | 1 | 1 | 0 | 0 |
| S2 | 1 | 1 | 1 | 0 | 1 | 1 |
위 예시에서는 2개 단어의 묶음 (bigram) 을 사용해서 표현했다.
만약 3개의 단어를 묶는다면 trigram이라고 부른다.
'AI LLM' 카테고리의 다른 글
| Word Embedding, Word2Vec (0) | 2025.06.07 |
|---|---|
| [NLP - 벡터 변환 알고리즘] TF-IDF (0) | 2025.05.25 |
| [NLP - 벡터 변환 알고리즘] One-Hot Encoding (0) | 2025.05.22 |
| [NLP] Lemmatization (표제어 추출), Stopwords(불용어) (2) | 2025.05.20 |
| [NLP] Tokenization(토큰화), Stemming(스테밍) (0) | 2025.05.19 |


